The post Node.js Promise — Использование промисов в серверной JavaScript appeared first on HackerX.
]]>В этой статье мы рассмотрим самые популярные из таких альтернатив, объекты Promise и генераторы, а также новейший синтаксис async await, который будет введен в JavaScript как часть спецификации ECMAScript 2017.
Мы увидим, как эти альтернативы могут упростить управление асинхронными потоками. И наконец, сравним все эти подходы, выявив плюсы и минусы каждого из них, чтобы иметь возможность разумно подойти к выбору подхода, наилучшим образом соответствующего требованиям проекта на платформе Node.js.
Объект Promise в JavaScript и Node.js
Стиль передачи продолжения (Continuation Passing Style, CPS) не является единственным способом реализации асинхронного кода. В действительности экосистема JavaScript предлагает интересные альтернативы традиционному шаблону обратных вызовов. Одной из самых распространенных таких альтернатив является объект Promise, которому уделяется все больше внимания, особенно сейчас, когда он стал частью спецификации ECMAScript 2015 и обрел встроенную поддержку, начиная с версии 4, платформы Node.js.
Что такое и для чего нужен Promise
Выражаясь простым языком, объект Promise является абстракцией, позволяющей функциям возвращать объект Promise, представляющий конечный результат асинхронной операции. Мы говорим, что объект Promise ожидает, если асинхронная операция еще не завершилась, выполнен – если операция завершилась успешно, и отклонен – если возникла ошибка. После того как объект Promise будет выполнен или отклонен, он считается установившимся.
Чтобы получить результат выполнения или ошибку (причину), вызвавшую отклонение, можно использовать метод then() объекта Promise:
promise.then([onFulfilled], [onRejected])
Здесь onFulflled() – это функция, которой передается результат выполнения асинхронной операции, а onRejected() – функция, которой передается причина отклонения. Обе функции являются необязательными.
Чтобы получить представление, как применение объектов Promise может изменить код, рассмотрим следующий фрагмент кода:
asyncOperation(arg, (err, result) => {
if(err) {
//обработка ошибки
}
//работа с результатом
});
Объекты Promise позволяют преобразовать этот типичный CPS-код в более структурированный и элегантный код, например:
asyncOperation(arg)
.then(result => {
//работа с результатом
}, err => {
//обработка ошибки
});
Одним из важнейших свойств метода then() является синхронный возврат другого объекта Promise. Если любая из функций – onFulflled() или onRejected() – вернет значение x, метод then() вернет один из следующих объектов Promise:
- выполненный со значением x, если x является значением;
- выполненный с объектом x, где x является объектом Promise или thenableобъектом;
- отклоненный с причиной отклонения x, где x является объектом Promise или thenableобъектом.
thenable-объект – это Promise-подобный объект, имеющий метод then(). Этот термин используется для обозначения объекта, фактическая реализация которого отличается от реализации Promise.
Эта особенность позволяет создавать цепочки из объектов Promise, облегчая объединение и компоновку асинхронных операций в различных конфигурациях. Кроме того, если не указывается обработчик onFulflled() или onRejected(), результат или причина отклонения автоматически направляется следующему объекту Promise в цепочке. Это дает возможность, например, автоматически передавать ошибку вдоль всей цепочки, пока она не будет перехвачена обработчиком onRejected(). Составление цепочек объектов Promise делает последовательное выполнение заданий тривиальной операцией:
asyncOperation(arg)
.then(result1 => {
//возвращает другой объект Promise
return asyncOperation(arg2);
})
.then(result2 => {
//возвращает значение
return 'done';
})
.then(undefined, err => {
// здесь обрабатываются все возникшие в цепочке ошибки
});
Схема на рисунке иллюстрирует другую точку зрения на работу цепочки объектов Promise:
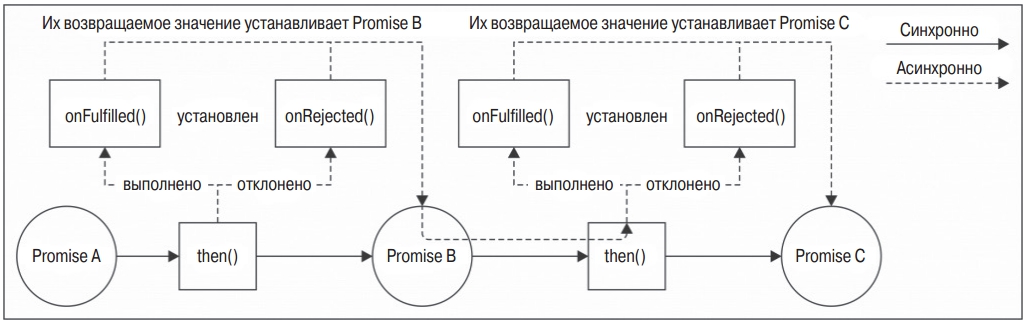
Другим важным свойством объектов Promise является гарантированный асинхронный вызов функций onFulflled() и onRejected(), даже при синхронном выполнении, как в предыдущем примере, где последняя функция then() в цепочке возвращает строку ‘done’. Такая модель поведения защищает код от непреднамеренного высвобождения Залго, что без дополнительных усилий делает асинхронный код более последовательным и надежным.
А теперь самое интересное: если в обработчике onFulflled() или onRejected() возбудить исключение (оператором throw), возвращаемый методом then() объект Promise автоматически будет отклонен с исключением в качестве причины отказа. Это огромное преимущество перед CPS, потому что исключение автоматически будет передаваться вдоль по цепочке, а это означает, что можно использовать оператор throw.
Исторически сложилось, что существует множество библиотек, реализующих объекты Promise, большинство которых не совместимо друг с другом, что препятствует созданию thenцепочек из объектов Promise, созданных разными библиотеками.
Сообщество JavaScript провело сложную работу по преодолению этого ограничения, в результате была создана спецификация Promises / A+. Эта спецификация детально описывает поведение метода then и служит основой, обеспечивающей возможность взаимодействий между объектами Promise из различных библиотек.
Реализации Promises/A+
Как в JavaScript, так и в Node.js есть несколько библиотек, реализующих спецификацию Promises/A+. Ниже перечислены наиболее популярные из них:
- Bluebird (https://npmjs.org/package/bluebird);
- Q (https://npmjs.org/package/q);
- RSVP (https://npmjs.org/package/rsvp);
- Vow (https://npmjs.org/package/vow);
- When.js (https://npmjs.org/package/when);
- объекты Promise из ES2015.
По существу, они отличаются только наборами дополнительных возможностей, не предусмотренных стандартом Promises/A+. Как упоминалось выше, этот стандарт определяет модель поведения метода then() и процедуру разрешения объекта Promise, но не регламентирует других функций, например порядка создания объекта Promise на основе асинхронной функции с обратным вызовом.
В примерах ниже мы будем использовать методы, поддерживаемые объектами Promise стандарта ES2015, поскольку они доступны в Node.js, начиная с версии 4, и не требуют подключения внешних библиотек.
Для справки ниже перечислены методы объектов Promise, определяемые стандартом ES2015.
Конструктор (new Promise(function(resolve, reject) {})): создает новый объект Promise, который разрешается или отклоняется в зависимости от функции, переданной в аргументе. Конструктору можно передать следующие аргументы:
- resolve(obj): позволяет разрешить объект Promise и вернуть результат obj, если obj является значением. Если obj является другим объектом Promise или thenableобъектом, результатом станет результат выполнения obj;
- reject(err): отклоняет объект Promise с указанной причиной err. В соответствии с соглашением err должен быть экземпляр Error.
Статические методы объекта Promise:
- Promise.resolve(obj): возвращает новый объект Promise, созданный из thenableобъекта, если obj – thenableобъект, или значение, если obj – значение;
- Promise.all(iterable): создает объект Promise, который разрешается результатами выполнения, если все элементы итерируемого объекта iterable выполнились, и отклоняется при первом же отклонении любого из элементов. Любой элемент итерируемого объекта может быть объектом Promise, универсальным thenableобъектом или значением;
- Promise.race(iterable): возвращает объект Promise, разрешаемый или отклоняемый, как только разрешится или будет отклонен хотя бы один из объектов Promise в итерируемом объекте iterable, со значением или причиной этого объекта Promise.
Методы экземпляра Promise:
- promise.then(onFulflled, onRejected): основной метод объекта Promise. Его модель поведения совместима со стандартом Promises/A+, упомянутым выше;
- promise.catch(onRejected): удобная синтаксическая конструкция, заменяющая promise.then(undefned, onRejected).
Стоит отметить, что некоторые реализации предлагают другой асинхронный механизм – механизм отложенных вычислений. Мы не будем рассматривать его, поскольку он не является частью стандарта ES2015.
Перевод функций в стиле Node.js на использование объектов Promise
В JavaScript не все асинхронные функции и библиотеки поддерживают объекты Promise изначально. Обычно типичные функции, основанные на обратных вызовах, требуется преобразовать так, чтобы они возвращали объекты Promise. Этот процесс называется переводом на использование объектов Promise.
К счастью, соглашения об обратных вызовах, используемые на платформе Node.js, позволяют создавать функции, способные переводить любые функции в стиле Node.js на использование объектов Promise. Это несложно осуществить с помощью конструктора объекта Promise. Создадим новую функцию promisify() и добавим ее в модуль utilities.js (чтобы ее можно было использовать в приложении вебпаука):
module.exports.promisify = function(callbackBasedApi) {
return function promisified() {
const args = [].slice.call(arguments);
return new Promise((resolve, reject) => { //[1]
args.push((err, result) => { //[2]
if(err) {
return reject(err); //[3]
}
if(arguments.length <= 2) { //[4]
resolve(result);
} else {
resolve([].slice.call(arguments, 1));
}
});
callbackBasedApi.apply(null, args); //[5]
});
}
};
Приведенная выше функция возвращает другую функцию – promisifed(), которая является версией callbackBasedApi, возвращающей объект Promise. Вот как она работает:
- функция promisifed() создает новый объект с помощью конструктора Promise и немедленно возвращает его;
- в функции, что передается конструктору Promise, мы передаем специальную функцию обратного вызова для вызова из callbackBasedApi. Поскольку функция обратного вызова всегда передается в последнем аргументе, мы просто добавляем ее в список аргументов (args) функции promisifed();
- если специальная функция обратного вызова получит ошибку, объект Promise немедленно отклоняется;
- в случае отсутствия ошибки осуществляется разрешение объекта Promise со значением или массивом значений, в зависимости от количества результатов, переданных функции обратного вызова;
- в заключение вызывается callbackBasedApi с созданным списком аргументов.
Большинство реализаций поддерживает вспомогательный метод преобразования типичных функций в стиле Node.js в функции, возвращающие объекты Promise. Например, библиотека Q содержит функции Q.denodeify() и Q.nbind(), библиотека Bluebird имеет Promise.promisify(), а When.js содержит node.lift().
Последовательное выполнение Промисов
Теперь, после знакомства с теорией, можно приступать к созданию приложений. Рассмотрим работу на примере создание веб-паука:
Код, который представлен ниже, не будет работать. Это просто пример использование.
const utilities = require('./utilities');
const request = utilities.promisify(require('request'));
const mkdirp = utilities.promisify(require('mkdirp'));
const fs = require('fs');
const readFile = utilities.promisify(fs.readFile);
const writeFile = utilities.promisify(fs.writeFile);
function download(url, filename) {
console.log(`Downloading ${url}`);
let body;
return request(url)
.then(response => {
body = response.body;
return mkdirp(path.dirname(filename));
})
.then(() => writeFile(filename, body))
.then(() => {
console.log(`Downloaded and saved: ${url}`);
return body;
});
}
Promise: Последовательные итерации
На данный момент, на примере приложения веб-паука, мы рассмотрели объекты Promise и приемы их использования для создания простой элегантной реализации последовательного потока выполнения. Но этот код обеспечивает выполнение лишь известного заранее набора асинхронных операций. Поэтому, чтобы восполнить пробелы в исследовании последовательного выполнения, нам нужно разработать фрагмент, реализующий итерации с помощью объектов Promise. И снова прекрасным примером для демонстрации станет функция spiderLinks().
function spiderLinks(currentUrl, body, nesting) {
let promise = Promise.resolve();
if(nesting === 0) {
return promise;
}
const links = utilities.getPageLinks(currentUrl, body);
links.forEach(link => {
promise = promise.then(() => spider(link, nesting – 1));
});
return promise;
}
Для асинхронного обхода всех ссылок на веб-странице нужно динамически создать цепочку объектов Promise.
- Начнем с определения «пустого» объекта Promise, разрешаемого как undefned. Он будет служить началом цепочки.
- Затем в цикле присвоим переменной promise новый объект Promise, полученный вызовом метода then() предыдущего объекта Promise в цепочке. Это и есть шаблон асинхронных итераций с использованием объектов Promise.
В конце цикла переменная promise будет содержать объект Promise, который вернул последний вызов then() в цикле, поэтому он будет разрешен после разрешения всех объектов Promise в цепочке.
The post Node.js Promise — Использование промисов в серверной JavaScript appeared first on HackerX.
]]>